
はじめに
こんにちは。データエンジニアの acchan です。
現在 DAP Lab とよばれるチームに配属しており、生成 AI 技術を使ったプロダクト開発に従事しています。生成 AI の新たな可能性と課題に挑む私たちの取り組みについて、今回は AI 出力改善のワークフロー構築に Argilla と呼ばれるツールを組み込んだ背景や、具体的な機能などについて紹介します。
導入背景
弊社はノーコードWebシステム改善プラットフォーム「テックタッチ」を展開しています。 この「テックタッチ」に対して、DAP Labでは生成 AI を使った機能(以下、AI 機能)のリリースを控えています。 この機能は「テックタッチ」の利用効率化を目的としたものです。しかし、初めてのリリースであるため、初期段階では AI モデルの生成結果がお客様の期待感を満たさないケースがたびたび起こり得る懸念があります。
具体的な問題点としては、生成される提案内容の正確性の欠如や一貫性のない回答、そしてお客様に混乱をもたらす結果を返してしまうことが挙げられます。
初期リリースの段階ではモデルの学習データや fine-tuning が不十分であることが予想され、期待するような精度や網羅性を持った回答を得るのは難しいと考えています。とはいえ、「初回リリース後も生成結果のクオリティをある程度担保できる状態としたい」というニーズも少なからずチーム内に存在していました。これは、お客様に早くから価値を感じていただき、その後も長くご利用いただくことが AI 機能にとって重要だと考えていたためです。したがって、期待に沿わないケースに対する継続的かつスピーディな改善が今後も求められていきます。
したがって今回構築する生成基盤では、入力データとそれに対応する修正結果に対して次の要件を満たす必要がありました。
- 人間の評価基準を照らし合わせ、より正しい方向へ生成結果を修正できる(いわゆる Human-in-the-Loop)
- 修正された結果を最終的な回答としてお客様へ提供できる
- 修正された結果を評価用データセットに追加して、今後の AI モデル改善に役立てる
この要件に対応すべくチームで調査を行ったところ、最終的には Argilla を使った改善サイクルを構築する方針となりました。
Argilla とは
Argillaは、AIエンジニアとドメインエキスパートが高品質なデータセットを構築するためのコラボレーションツールです。半年前に機械学習モデルのプラットフォームを運営する Hugging Face 社にジョインしたように、同社サービスの Hugging Face との親和性の高さが魅力です。
公式ドキュメントによると次のような特徴を持つとしています。
- データ品質の向上: 高品質な基準を維持し、AIの出力品質を改善することができます
- データとモデルの制御: ブラックボックス化を避け、データとモデルの所有権を保持できます
- 効率的な反復: フィルター、AI フィードバック提案、セマンティック検索を通じて、データとの対話が容易になります
主なユースケースとしては大規模言語モデル(LLM)や自然言語処理(NLP)をターゲットとした「データセット開発」「モデル開発」が挙げられます。データセットの収集はもちろん、AI モデルの出力を人間がチェックするなどの用途にも活用できます。
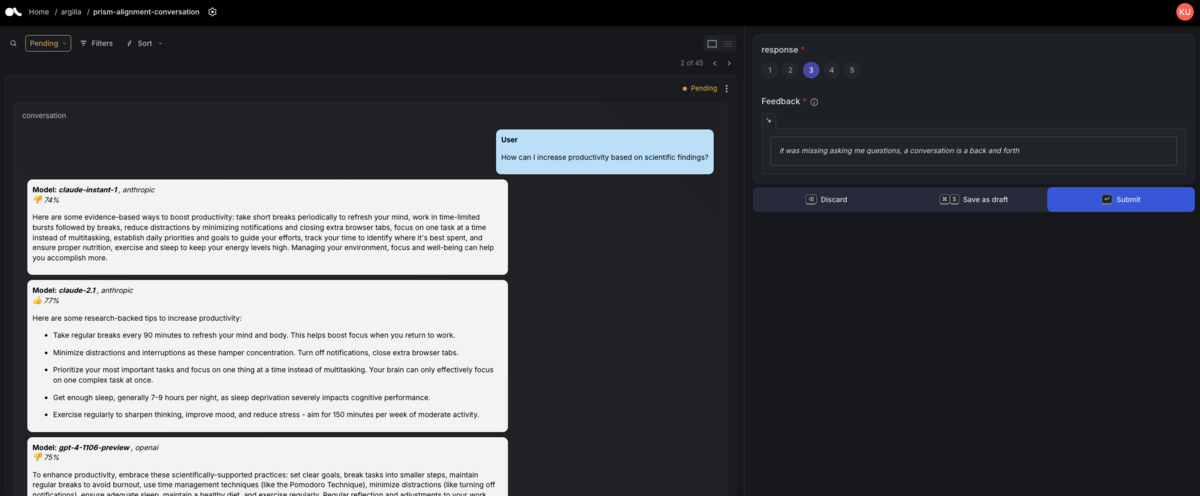
なぜ Argilla を選んだか
Argilla を選定するに至った理由をざっと箇条書きで示しますと次のようになります。
- 評価 UI が直感的でわかりやすい
- 評価・アノテーション設計の柔軟性が高い
- 自然言語のラベリングだけでなく、画像や音声を用いたデータに対するアノテーションや評価もできる
- データセットを Python SDK で作成できる
- 生成基盤内のデータ入出力が容易
- Argilla へのデータ挿入や評価済みデータの外部システムへの出力も Python SDK で実現できる
このように、UI のユーザビリティとデータセット開発の高い柔軟性といった評価側・開発側双方にとってフレンドリーな構成となっていることが大きな決め手となりました。
実現したいこと
Argilla を AI 機能の生成基盤に組み込むために行ったことについて紹介します。
設計
本機能のワークフローは大まかに以下の流れとしました。

- 日次バッチ
- データの前処理(図中の入力データ〜加工データ)
- AI モデルにデータを入力して推論を実行
- 生成結果を Argilla データセットに追加
- 追加された生成物をレビュワーが評価
- 評価を通して修正された生成物をお客様の「テックタッチ」へ提案
- AI モデル改善時の評価データセットとして利用する(図中のフィードバック)
実装方針
ここでは上記ワークフローのうち、主に Argilla に関わる「生成結果を Argilla データセットに追加」と「追加された生成物をレビュワーが評価」部分の実装方針にフォーカスして説明します。
開発で Argilla サーバを立ち上げる際、docker コンテナを用いる方法と Hugging Face Spaces 上にデプロイする方法のいずれかが選択できます。今回は後者を使って説明します。
データセットの作成
まずデータセットの作成先として workspace を Argilla 上に作成します。名前は便宜上”blog_sample”としています。workspace は Argilla における名前空間のようなもので、データセットの集合を表しています。
import argilla as rg #Hugging Face Spaces で立ち上げた場合は以下で接続 client = rg.Argilla( api_url="https://[huggingface-username]-[space-name].hf.space", api_key="YOUR_API_KEY", # headers={"Authorization": "Bearer {YOUR_HF_TOKEN}"}, # private space の場合は access token も必要 ) # docker などを利用する場合は以下 # client = rg.Argilla(api_url="http://localhost:6900", api_key="YOUR_API_KEY") workspace_to_create = rg.Workspace(name="blog_sample") workspace_to_create.create() print("Workspace blog_sample has been created.")
データセットの作成を行います。Settings クラスにてデータスキーマやアノテータに回答してもらう課題などを定義し、データセットの create メソッドを呼び出します。
settings = rg.Settings(
fields=[
rg.TextField(name="title", title="Title", required=True),
rg.TextField(name="content", title="Content", required=True),
],
metadata=[
rg.TermsMetadataProperty(name="author", visible_for_annotators=False),
rg.TermsMetadataProperty(name="published_at", visible_for_annotators=False),
],
questions=[
rg.RatingQuestion(name="rating", values=[1, 2, 3, 4, 5], title="Rating", required=True),
],
guidelines="Please rate the article from 1 to 5.",
)
dataset = rg.Dataset(
name="blog_sample",
settings=settings,
workspace="blog_sample",
)
dataset.create()
データセットの各フィールドについては以下の通りとなります(詳しくはドキュメント参考)。
- Field:メインとなるスキーマ。評価 UI 上に表示されるデータとなる
- Metadata:レコードに付与する追加情報。後述するフィルタやソートに利用可能
- Question:アノテータに回答してもらうための質問を定義
- Guideline:アノテータにタスクを理解してもらうためのガイドラインを記述
推論結果の挿入
推論結果は Record オブジェクトとして Dataset へ挿入します。今回はダミーレコードを生成してデータセットに挿入してみます。流れとしては、事前に Record オブジェクトのリストを用意しておき、データセットオブジェクトの log メソッドを呼び出します。
from typing import Any def dummy_record_generator(size: int = 3) -> Generator[rg.Record, Any, None]: for i in range(size): yield rg.Record( fields={ "title": f"Title {i}", "content": f"Content {i}", }, metadata={"author": "John Doe", "published_at": "2022-01-01"}, ) records = list(dummy_record_generator()) dataset.records.log( records=records, # batch_size=256, # 一度に送信するレコード数を指定可能。request size exceeded エラーが出た場合はこちらを調整する )
このメソッドはレコードの更新にも利用できます。例えば、データセットの metadata.author が”John Doe” であるレコードを更新する場合の処理は次のようになります。
# データセットからレコードを取得する existing_records = list(dataset.records(rg.Query(filter=rg.Filter(("metadata.author", "==", "John Doe"))))) updated_records = [] for record in existing_records: record.metadata["author"] = "Jane Doe" updated_records.append(record) dataset.records.log(records=updated_records)
既存レコードの取得に Filter オブジェクトを用いて条件指定をしています。3つの文字列からなるタプルで記述を行い、1項目にレコードのフィールド名、2項目に演算子、3項目に値を入力します(利用可能なフィールドや演算子などはドキュメントを参考)。
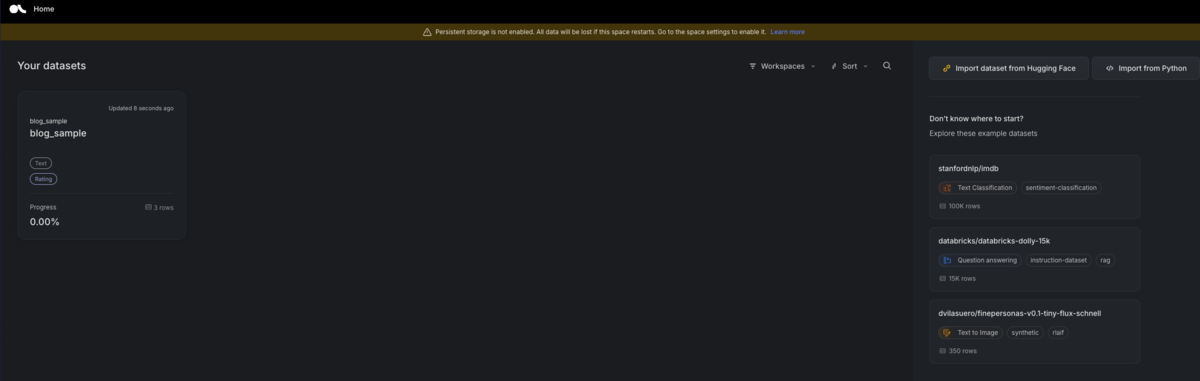
実際に Argilla にアクセスして確認してみます(Admin ロールを持つユーザでアクセスしてください)。データセットが正常に追加されている場合は、以下の一覧に表示されているはずです。
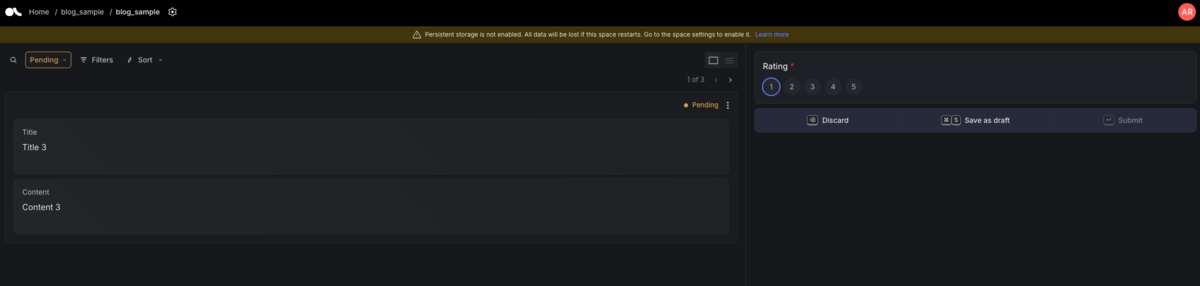
データセットのカードをクリックすると、評価 UI が表示されます。左半分にレコードの Field、右半分に Question が表示されます。今回の例では1から5までのいずれかを選択して Submit ボタンをクリックする流れとなりますが、キーボードの数字を入力して送信することも可能です。
評価結果の取得
アノテータが評価したデータを取得する場合は、次のような形で実現されます。
filter = rg.Filter( [ ("status", "==", "completed"), ("response.status", "==", "submitted"), ] ) records = dataset.records(rg.Query(filter=filter))
ここでは status と response.status それぞれに対する条件を指定しています。
前者はレコード自体のステータス(pending,completed)、後者はアノテータの操作によって設定されるステータスを指しています(draft,submitted,discarded)。アノテータによるなんらかの操作(下書き保存、評価の送信、棄却)が行われた時点で、レコードのステータスが completed に変更されるようです。この場合は評価が完了したデータを取得したいため、前者に加えて後者の条件を付け加えています。
取得したレコードは Hugging Face の Dataset や、 Python 辞書を通して pandas の DataFrame に変換することが可能です。
# Hugging Face dataset hf_dataset = records.to_datasets() # pandas.DataFrame df = pd.DataFrame.from_dict(records.to_dict(flatten=True, orient="names"))
その他実装における工夫点
Argilla 以外の生成基盤全体の実装における工夫点は次のとおりです。それぞれ詳しい詳細は割愛します。
- 日次バッチのジョブ実装は dagster を使用しました
- 弊社の分析基盤で採用されている実績があるほか、OpenAI API の関数呼び出し回数や入力トークンなどが時系列で確認できる機能を持つなどオブザーバビリティ面でも優れている点があるため(参考ブログ)
- 提案データをお客様環境へ送信する際の課題として、Argilla での評価状況はその性質上リアルタイムで変動するため、どのように提案を更新していくかが課題となりました
- そこで一定時間ごとに評価済み件数をポーリングして、時間内に評価されたデータをDBへ追加する処理を実装しました
- こちらは dagster の sensor を活用しました
今後の課題
生成基盤を運用していくうえでの課題点を挙げます。
- (OSS を運用するうえでの宿命かもしれませんが)Argilla の開発スピードが非常に早く、運用を開始してからのメンテナンスをどうするかよく考える必要がある
- 人間が関与するプロセスが挟まることによる価値提供の遅延を克服する必要がある
- 初期リリース段階では、「評価結果をデータセットとして蓄積すること」および「お客様へできる限り期待に沿う回答を出力すること」に注力すべく、ラグは許容できるものとしています
- いずれ AI モデルの改善によってある程度の精度を保証できるようになった段階で、一部のみ AI による結果をそのままお客様へ提供するなどして、段階的に Argilla の評価ステップを廃止する方針を考えています
まとめ
今回は生成 AI の出力品質向上の一環として、人間の評価をワークフローに組み込むために Argilla を導入した背景と実装の工夫について紹介しました。
Argilla の使い勝手などに興味のある方は、Hugging Face でデモ環境を触ることができますので気軽に試してみてくださいね。
本記事がなにかの参考になれば幸いです🙇