
この記事はテックタッチアドベントカレンダー22日目の記事です。
こんにちは。データアナリストの bibi です。今回初めてアドベントカレンダーの記事を書きます。よろしくお願いいたします!
2020年12月に入社してからちょうど1年が経ちました。 私の主な業務はデータの取得で、毎日クエリを書きながら、様々なチームの意思決定のサポートをしています。
データの取得クエリは時に非常に複雑になることがありますが、 その一つである、SQLでのリレーション代数系のクエリを解決する方法について、この記事で紹介します。 PostgreSQLのSQLを利用して説明します。
はじめに
データベース独自の関係演算は4つあります。
- 選択 (Selection)
- 射影 (Projection)
- 結合 (Join)
- 商 (Division)
選択演算は where, on, having 句、射影は select 句を使います。結合には except, union, cross join などをよく使います。最後の商(Division)演算ですが、定義は
表 S の全ての属性の値を同時に満たす表 R の行を選び出し、 S の属性を取り除いた列を取り出す演算である。
です。複数条件があるデータは商演算となります。
実際の場面で使用する商演算の例としては以下のようなものが上げられます。
- 一度もガイドを再生したことがないシステム利用中のユーザーを取得する
Find all users who are using the systems but never started any guide - 特定求人のスキルを持っている候補者を取得する
Find all candidates who match all skills for a certain job position - 対象システムを毎月一回以上利用しているユーザーを取得する
Find all users who are using the systems at least once every single month
複雑になりがちな商演算のクエリの例と解決法を、以下のサンプルデータベースを使って説明していきます。
サンプルデータベース
従業員が利用中のシステムが登録されたデータベースを dbfiddle に用意しました。 実際にクエリを試すこともできますので、この記事を読みながら是非クエリを試してみてください。
EmployeeAppSystemDB dbfiddle.uk
- ER図

EmployeeAppSystemDB Tables
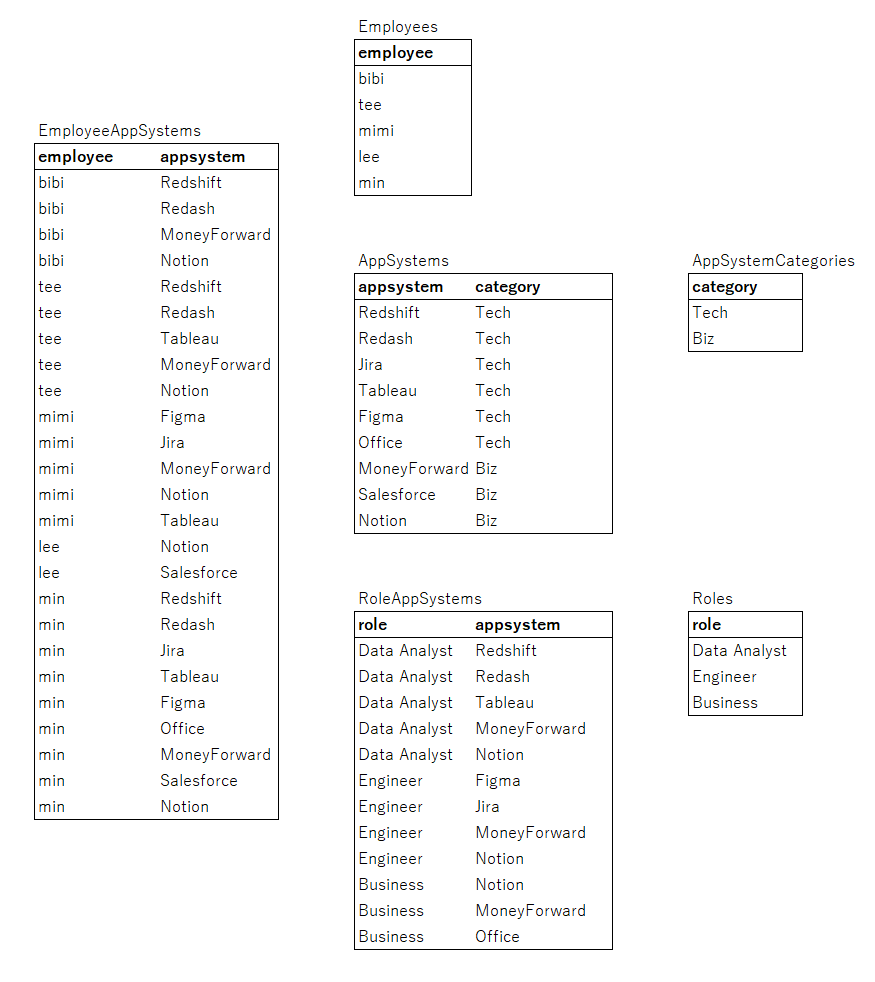
EmployeeAppSystemDB's Tables データの説明
- Employee:社員の名前データ
- EmployeeAppSystems:社員が利用するシステムのデータ
- AppSystems:システムの情報
- AppSystemCategories:システムタイプの情報
- RoleAppSystems:ロール毎に割り当てるシステム
- Roles:社員のロール
以上のデータベースから、以下の質問に答えるための情報を抽出していきていきます。
- 全てのシステムを利用する社員の抽出
Who, among the employees, uses all the app systems? - データアナリスト用システムを利用する社員の抽出
Who, among the employees, uses the app systems for Data Analyst? - データアナリスト用システムのみを利用する社員の抽出
Who, among the employees, uses only the app systems for Data Analyst?
複雑になってしまっている例
まず、複雑になってしまっている例を見ていきましょう。 これも間違いではないですが、考え方とクエリが複雑になりすぎてしまっています。
① 全てのシステムを利用する社員の抽出
all_app_systems全てのシステムを取得して、全ての社員とcross joinして直積結合を作ります。employee_not_using_all_systems「全てのシステムを利用する」とは、使わないシステムがないという事なので、all_app_systemsから使わないシステムがある社員を取得します。- 使わないシステムがある社員を
Employeeから除外すれば、全てのシステムを利用する社員が取得できます。
with /* 全てのシステムを取得して、全ての社員と cross join して直積結合を作ります。*/ all_app_systems as ( select * from (select distinct(AppSystem) as AllAppSystems from AppSystems) as app_systems cross join Employees ), /*「全てのシステムを利用する」とは、使わないシステムがないという事なので、 all_app_systems から使わないシステムがある社員を取得します。*/ employee_not_using_all_systems as ( select all_app_systems.Employee from all_app_systems left join EmployeeAppSystems as eas on eas.AppSystem = all_app_systems.AllAppSystems and eas.Employee = all_app_systems.Employee where eas.Employee is null group by all_app_systems.Employee ), /* 使わないシステムがある社員を`Employee`から除外すれば、 全てのシステムを利用する社員が取得できます。*/ employee_uses_all_systems as ( select e.Employee from Employees as e left join employee_not_using_all_systems as n on e.Employee = n.Employee where n.Employee is null ) select * from employee_uses_all_systems;
結果
| employee |
|---|
| min |
クエリの長さ:36行
② データアナリスト用システムを利用する社員の抽出
- 全てのシステムではなく、データアナリスト用システムを利用する社員を対象とします。
- 上のクエリと同じ考え方で、
cross joinのところだけ、RoleAppSystemsのRole = 'Data Analyst'で絞り込んでから直積結合を作ります。
with /* データアナリスト用システムを取得して、 全ての社員と cross join して直積結合を作ります。*/ data_analyst_systems as ( select * from (select distinct(AppSystem) as DataAnalystAppSystems from RoleAppSystems where Role = 'Data Analyst' ) as app_systems cross join Employees ), /* データアナリスト用システムを使わない社員を取得します。*/ employee_not_using_da_systems as ( select das.Employee from data_analyst_systems as das left join EmployeeAppSystems as eas on eas.AppSystem = das.DataAnalystAppSystems and eas.Employee = das.Employee where eas.Employee is null group by das.Employee ), /* 全ての社員からデータアナリスト用システムを使わない社員を除外します。*/ employee_uses_da_systems as ( select e.Employee from Employees as e left join employee_not_using_da_systems as n on e.Employee = n.Employee where n.Employee is null ) select * from employee_uses_da_systems;
結果
| employee |
|---|
| tee |
| min |
クエリの長さ:39行
③ データアナリスト用システムのみを利用する社員の抽出
- データアナリスト用システムのみを使う社員だけを対象とする場合は、データアナリスト用システム以外に他のシステム(以下の画像の灰色の行)も使う社員を除外することとなります。
employee_uses_notonly_da_systemsでデータアナリスト用システムを利用する社員の内、他のシステムも利用する社員を取得します。employee_uses_only_da_systemsでデータアナリスト用システムを利用する社員から他のシステムも利用する社員を除外して、完成します。
min社員はデータアナリスト用システムを利用するが、他のシステムも利用するので、データアナリスト用システムのみを利用するグループから除外します。
with /* データアナリスト用システムを取得して、 全ての社員と cross join して直積結合を作ります。*/ data_analyst_systems as ( select * from (select distinct(AppSystem) as DataAnalystAppSystems from RoleAppSystems where Role = 'Data Analyst' ) as app_systems cross join Employees ), /* データアナリスト用システムを使わない社員を取得します。*/ employee_not_using_da_systems as ( select das.Employee from data_analyst_systems as das left join EmployeeAppSystems as eas on eas.AppSystem = das.DataAnalystAppSystems and eas.Employee = das.Employee where eas.Employee is null group by das.Employee ), /* 全ての社員からデータアナリスト用システムを使わない社員を除外し、 データアナリスト用システムを利用する社員を取得します。*/ employee_uses_da_systems as ( select e.Employee from Employees as e left join employee_not_using_da_systems as n on e.Employee = n.Employee where n.Employee is null ), /* データアナリスト用システムもほかのロール用システムも利用する社員を取得します。 */ employee_uses_notonly_da_systems as ( select da.Employee from employee_uses_da_systems as da left join EmployeeAppSystems as eas on da.Employee = eas.Employee left join (select * from RoleAppSystems where Role = 'Data Analyst') as ras on eas.AppSystem = ras.AppSystem where ras.Role is null group by da.Employee ), /* データアナリスト用システムを利用する社員から他のロール用システムも利用する社員を除外します。*/ employee_uses_only_da_systems as ( select e.Employee from employee_uses_da_systems as e left join employee_uses_notonly_da_systems as n on e.Employee = n.Employee where n.Employee is null ) select * from employee_uses_only_da_systems;
結果
| employee |
|---|
| tee |
クエリの長さ:64行
商演算の定義通り実行された以上の3つのクエリの結果は正しいですが、クエリの内容が読みづらいのと、複雑な結合を使ったことで、クエリを検証する時やレビューする時に、手間がかかって大変ですね。。。 以下に別のより分かりやすいアプローチを紹介します。
集計関数を使う方法(Aggregation)
① 全てのシステムを利用する社員の抽出
- 「全てのシステムを利用する社員の利用システム数」=「AppSystemsの個別カウント」と考えられるので、集計関数を利用すれば一つのクエリで解決出来ます。
group byしてから、集計を行うごとにhaving句で集計関数を実行するとなります。
/*「全てのシステムを利用する社員の利用システム数」=「AppSystemsの個別カウント」*/ select eas.Employee from EmployeeAppSystems as eas group by eas.Employee having count(*) = ( select count(*) from AppSystems group by () );
結果
| employee |
|---|
| min |
クエリーの長さ:36行 → 15行に減りました
② データアナリスト用システムを利用する社員の抽出
全てのシステムではなく、データアナリスト用システムを利用する社員を対象とする場合を考えます。
- データアナリスト用システムに限られるので、まず
data_analyst_systemsでAppSystemsから、データアナリスト用システムを取得します。 EmployeeAppSystemsをデータアナリスト用システムで絞り込むように、data_analyst_systemsはフィルター用クエリとして、EmployeeAppSystemsとinner joinします。- 上記と同じ考え方で、count()集計関数を運用して解決できます。
with /* データアナリスト用システムを取得します。*/ data_analyst_systems as ( select rs.AppSystem from RoleAppSystems as rs where rs.Role = 'Data Analyst' ) /* データアナリスト用システムを利用する社員を取得します。*/ select eas.Employee from EmployeeAppSystems as eas inner join data_analyst_systems as das on das.AppSystem = eas.AppSystem group by eas.Employee having count(*) = (select count(*) from data_analyst_systems);
結果
| employee |
|---|
| tee |
| min |
クエリの長さ:39行 → 20行に減りました
※注意点:inner joinを利用しているので、「結果に表れた社員がデータアナリスト用システムだけを利用する」とは言えません。「データアナリスト用システムのみを利用する写真」の計算は③の方法となります
③ データアナリスト用システムのみを利用する社員の抽出
データアナリスト用システムを利用する社員のうち、データアナリスト用システムに加えてそれ以外のシステムも使う社員がいると考えられます。その社員を含まず、データアナリスト用システムのみを使う社員だけを対象とする場合を以下で説明します。
- データアナリスト用システムを取得します。
- 今回は、「データアナリスト用システム以外のシステムを使う社員を含まない」という条件で、全体のcount(*)へのマッチ条件だけではなく、「Data Analyst」というRoleのシステム数と社員の利用システム数もマージします。
with /* データアナリスト用システムを取得します。*/ data_analyst_systems as ( select rs.AppSystem from RoleAppSystems as rs where rs.Role = 'Data Analyst' ) /* データアナリスト用システムのみを利用する社員を取得します。*/ select eas.Employee from EmployeeAppSystems as eas left outer join data_analyst_systems as das on das.AppSystem = eas.AppSystem group by eas.Employee having count(das.AppSystem) = (select count(*) from data_analyst_systems) and count(das.AppSystem) = count(*);
結果
| employee |
|---|
| tee |
クエリーの長さ:64行 → 21行に減りました
集合演算を使用する(Set Operators)
集合演算とはUNION, INTERSECT, EXCEPTのことです。詳しくはこちらをご覧ください。
① 全てのシステムを利用する社員の抽出
- 言い換えると、「全てのシステムを利用する社員」は「利用するシステム以外のシステムが存在しない社員」となります。
The employee for whom the set of all systems except for the ones he uses is empty - 言い換えた言葉のロジック通りに、SQLの
not existsとexceptで表現出来ます
「存在しない」=not exists
「以外」=except
-- 全てのシステムを利用する社員 -- 利用するシステム以外の全てのシステムはない社員 select e.Employee from Employees as e where not exists ( -- 全ての利用されるシステム select a.AppSystem from AppSystems as a except -- 利用するシステム以外 select eas.AppSystem from EmployeeAppSystems as eas where eas.Employee = e.Employee )
結果
| employee |
|---|
| min |
クエリの長さ:36行 → 21行に減りました
② データアナリスト用システムを利用する社員の抽出
全てのシステムではなく、データアナリスト用システムを利用する社員を対象とします。
- 言い換えると、「利用するシステム以外のデータアナリスト用システムが存在しない社員」を取得することとなります
- 全ての利用されるシステムのクエリの代わりに、データアナリスト用システムのクエリに変更するだけで完成です
-- データアナリスト用システムを利用する社員 -- 利用するシステム以外の全てのデータアナリスト用システムはない社員 select e.Employee from Employees as e where not exists ( -- 全ての利用されるデータアナリスト用システム select ra.AppSystem from RoleAppSystems as ra where ra.Role = 'Data Analyst' except -- 利用するシステム以外 select eas.AppSystem from EmployeeAppSystems as eas where eas.Employee = e.Employee )
結果
| employee |
|---|
| tee |
| min |
クエリーの長さ:39行 → 20行に減りました
③ データアナリスト用システムのみを利用する社員の抽出
先の例を見たとき、集合演算を使うとかなり直感と反してしまうため、クエリが短くなったとしてもあまり有効な方法ではなくなってしまいます。
select e.Employee from Employees as e where NOT EXISTS ( -- 全ての利用されるデータアナリスト用システム select ra.AppSystem from RoleAppSystems as ra where ra.Role = 'Data Analyst' EXCEPT -- 利用するシステム以外 select eas.AppSystem from EmployeeAppSystems as eas where eas.Employee = e.Employee ) and NOT EXISTS ( -- 利用するシステム select eas_2.AppSystem from EmployeeAppSystems as eas_2 where eas_2.Employee = e.Employee EXCEPT -- データアナリスト用システム select ra_2.AppSystem from RoleAppSystems as ra_2 where ra_2.Role = 'Data Analyst' )
おわりに
長くなってしまいがちな商演算のクエリは
- 集計関数を使う方法:
count(),sum(),max()を活用する - 集合関数を使う方法:
exceptとnot existsダブルネガティブのロジックを使う
のアプローチで、シンプルに書くことができるのでおすすめです。
Hope you find this approach to relational division helpful!
Merry Christmas and Happy New Year ✨
参考資料
- Camps, D. (2021, August 16). High Performance Relational Division in SQL server. Simple Talk. Retrieved December 21, 2021, from https://www.red-gate.com/simple-talk/databases/sql-server/learn/high-performance-relational-division-in-sql-server/
- Celko, J. (2021, September 29). Divided we stand: The SQL of relational division. Simple Talk. Retrieved December 21, 2021, from https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/divided-we-stand-the-sql-of-relational-division/
- GeeksforGeeks. (2018, March 21). SQL: Division. GeeksforGeeks. Retrieved December 21, 2021, from https://www.geeksforgeeks.org/sql-division/
- HA. (2013, January 4). データベースの学習-その2表の操作の考え方(関係代数). ドリームサポートネットーワークのブログ. Retrieved December 21, 2021, from https://ameblo.jp/d-s-network/entry-11442328489.html
- LinkedIn Learning. (2021). Advanced SQL: High Performance Relational Divisions. Retrieved December 21, 2021, from https://www.linkedin.com/learning/advanced-sql-high-performance-relational-divisions/relational-algebra?autoAdvance=true&autoSkip=false&autoplay=true&resume=true.
- Mikku. (2018). 第一部9番 SQLで集合演算. In 達人に学ぶSQL徹底指南書: 初級者で終わりたくないあなたへ (2nd ed., pp. 179–196). chapter, Shōeisha.
- PostgreSQL Global Development Group. (2001). リレーショナルデータモデルの操作. PostgreSQL 7.1.2 ドキュメント(日本語版 1.0). Retrieved December 21, 2021, from https://cellbank.nibiohn.go.jp/legacy/information/pc/postgres_man/relmodel-oper.html
- 麗澤大学授業教材集. (n.d.). リレーショナル代数の基礎. 麗澤大学 大学ITソリューションセンター. Retrieved December 21, 2021, from http://www.cs.reitaku-u.ac.jp/infosci/rdb/rdb02.html