
この記事はテックタッチアドベントカレンダー21日目の記事です。
プロダクトオーナーの尾崎です。今年のクリスマスは肉のハナマサの冷凍丸鶏をローストチキンにして楽しみました。オーブンさえあれば意外と簡単なのでおすすめです。

この記事では、AWS Elasticsearch Serviceへの分析用クエリをSQLで記述し、Redashから利用できるか検証した顛末をご紹介します。
背景
テックタッチではデータストアとしてMySQL, AWS Elasticsearch Service、BIツールとして Redashを利用*1しています。
私自身も各種分析のためにクエリを書くことがあるのですが、Elasticsearchのクエリになかなか馴染むことが出来ず、毎回それなりに時間をかけて*2クエリを書いているため、より効率的に業務を進めるためにリサーチすることにしました。
Open Distro for Elasticsearchとは
2019年3月にAWSがElasaticsearchの別ディストリビューションとして Open Distro for ElasticSearchを公開しました。
AWSのOSSに対する態度については議論があるようですが、もともとのAmazon Elasticsearch Serviceに加えて、以下の機能が追加されている強力なディストリビューションです。
- 高度なセキュリティ(node to nodeの暗号化、ADやSAMLなど5種類の認証、RBAC、監査ログなど)
- イベントモニタリング&アラート(indexが特定の条件を満たした場合、slackなどで通知)
- クラスタやノードのパフォーマンス分析
- SQLサポート
Amazon Elasticsearch Serviceの歴史的な経緯やElastic社が提供するサービスとの違いについてはこちらの資料が大変参考になりました。ありがとうございます。
KibanaでSQLを試す
テスト用のElasticsearchドメインを生成(ver 7.9)し、Kibanaからサンプルデータとして、"Sample web logs"を流し込みました。
データの内容は、UserAgent、IPアドレス、アクセスしたページのパスなどが記録されている一般的なwebのアクセスログです。
GET /kibana_sample_data_logs/_mapping
例として、「ページのURLにelasticsearch 含むページのユーザーごとのページビュー」を計算するクエリを書いてみます。
ここでは、1ユーザーを識別するkeyとして、便宜的にIPアドレスとUserAgentの組み合わせを使っています。
select count(*) as pv_per_user from kibana_sample_data_logs where timestamp between '2020-12-06' and '2020-12-20' and request like '%elasticsearch%' group by clientip, agent
注:これは後述の通り不完全なクエリ
Kibanaのメニュー「Query Workbench」から簡単にSQLを実行することができます。
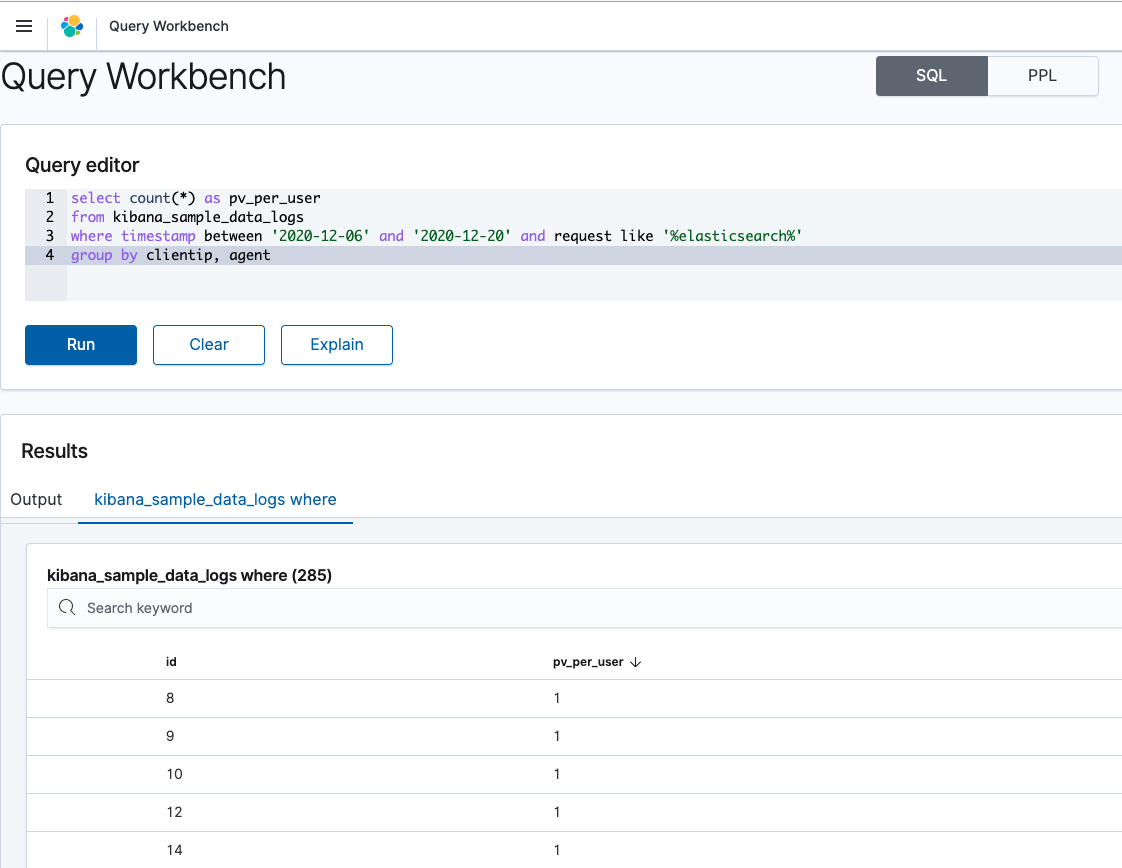
Explainボタンを押すと、SQLが実際にどのようなElasticSearchクエリとして変換されたかを確認することができます。自前でこのようなクエリを作るのは、それなりにElasticsearchの経験が必要そうです。大変便利ですね。
{ "from": 0, "size": 0, "query": { "bool": { "filter": [ { "bool": { "must": [ { "bool": { "must": [ { "range": { "timestamp": { "from": "2020-12-06", "to": "2020-12-20", "include_lower": true, "include_upper": true, "boost": 1 } } }, { "wildcard": { "request": { "wildcard": "*elasticsearch*", "boost": 1 } } } ], "adjust_pure_negative": true, "boost": 1 } } ], "adjust_pure_negative": true, "boost": 1 } } ], "adjust_pure_negative": true, "boost": 1 } }, "_source": { "includes": [ "COUNT" ], "excludes": [] }, "aggregations": { "clientip": { "terms": { "field": "clientip", "size": 200, "min_doc_count": 1, "shard_min_doc_count": 0, "show_term_doc_count_error": false, "order": [ { "_count": "desc" }, { "_key": "asc" } ] }, "aggregations": { "agent.keyword": { "terms": { "field": "agent.keyword", "size": 10, "min_doc_count": 1, "shard_min_doc_count": 0, "show_term_doc_count_error": false, "order": [ { "_count": "desc" }, { "_key": "asc" } ] }, "aggregations": { "pv_per_user": { "value_count": { "field": "_index" } } } } } } } }
Explainの結果を確認すると、aggregationsにsize: 200やsize: 10が設定されていることがわかります。このままでは集計対象のドキュメントが制限されてしまうので、正確な集計ができません。この現象はgithubのイシューでも報告されている現象ですが、以下のようにSQLを変更することで制限を回避することが出来ました。参考
select count(*) as pv_per_user from kibana_sample_data_logs where timestamp between '2020-12-06' and '2020-12-20' and request like '%elasticsearch%' group by terms('field'='clientip','size'=10000,'alias'='clientip'), terms('field'='agent.keyword','size'=10000,'alias'='agent')
RedashからElasticsearchにSQLを実行できるか
Redash Version: 8.0.0+b32245 (a16f551e) で動作確認
RedashのPython Datasourceから以下のようなコードを実行してみました。
※PythonのElasticsearchクライアントは現時点で/_opendistro/_sqlに対応していないように見えたので、requestsモジュールで直接REST APIにアクセスしています。
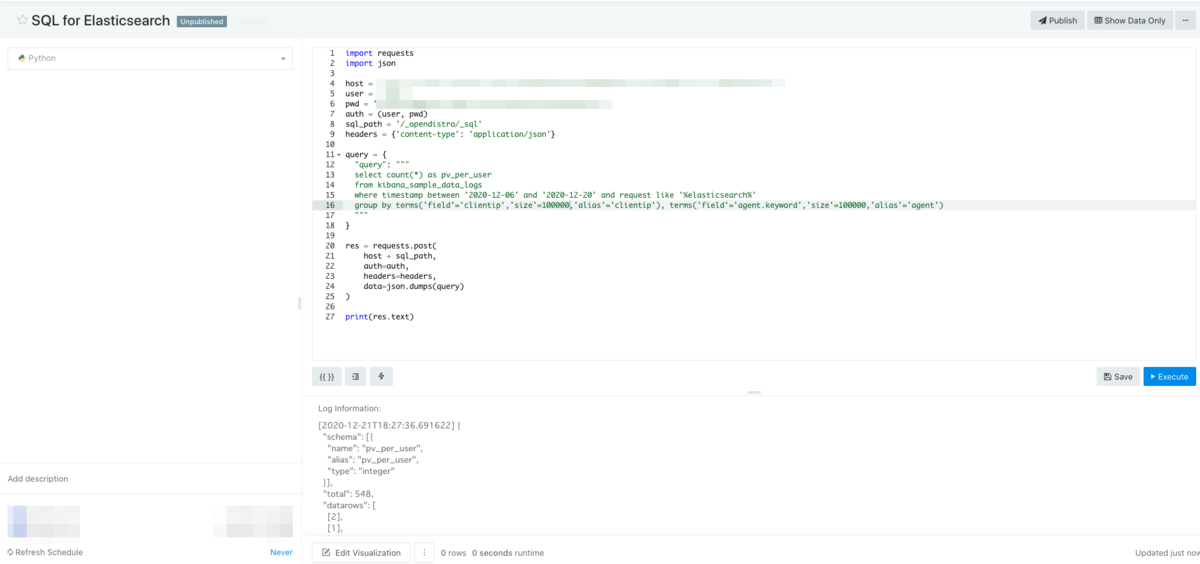
import requests import json host = 'YOUR_ENDPOINT' user = 'USER_NAME' pwd = 'PASSWORD' auth = (user, pwd) sql_path = '/_opendistro/_sql' headers = {'content-type': 'application/json'} query = { "query": """ select count(*) as pv_per_user from kibana_sample_data_logs where timestamp between '2020-12-06' and '2020-12-20' and request like '%elasticsearch%' group by terms('field'='clientip','size'=100000,'alias'='clientip'), terms('field'='agent.keyword','size'=100000,'alias'='agent') """ } res = requests.post( host + sql_path, auth=auth, headers=headers, data=json.dumps(query) ) print(res.text)
レスポンス res.textはこのような形で取得できました。問題なさそうですね。
{ "schema": [{ "name": "pv_per_user", "alias": "pv_per_user", "type": "integer" }], "total": 548, "datarows": [ [2], [1], [2], [1], [2], [1], [2], [1], [1], [1], [1], ...... ], "size": 548, "status": 200 }
感想、まとめ
- SQL→Elasticsearchのクエリへの変換は完璧ではないため(利用できる関数も制限あり)、利用前には必ずExplain結果を確認することが望ましいと思います。
- 意図通りのクエリが実行できなかった場合はElasticsearchの知識が必要になります。
- KibanaのWorkbenchはエラー表示がまだまだ親切ではないため、開発者ツールのNetworkタブを使って、実際のAPIからの返り値を確認する方法が便利でした。
- Elastic社の提供するX-PackにもSQLサポート機能が含まれているので、比較してみるとよさそうです。
- 検証の主目的ではなかったものの、キャッチアップできていなかったKibanaの進化(マルチテナント向け機能やCognito認証)を知る良い機会になりました。
以上、簡単ではありますが、Amazon Elasticsearch Service × RedashでSQLを使えるか検証しました。
結論:
「SQLだけでElasticsearchのクエリが書ける!」という段階ではなく、機能が成熟するまでもう少し時間が必要そうな印象を受けました。
2020年12月時点では、Elasticsearchのクエリを主軸にしつつ、SQLはクエリ生成をサポートするための位置付けとして使っていくのが現実的な利用方法と思われます。
明日の記事は、「テックタッチのテックタッチの使い方」です。
*1:昨年のアドベントカレンダーではこんな記事を書いていました。https://qiita.com/ikazo_y/items/5312144346dd028ab9ba
*2:クエリ結果がネストしていた場合や複数のクエリを1つの表にまとめるためにPython data sourceを利用していることも一因